Folgender Gastbeitrag stammt von der Firma Adacor Hosting GmbH, welchem ich voll ganz zustimme.
Softwareentwicklung besitzt oftmals einen hohen Stellenwert in einem Unternehmen. Doch nach wie vor sind spezialisierte Softwareentwickler eine begehrte Mangelware auf dem Arbeitsmarkt und dementsprechend schwer zu finden. Zudem gehören Softwareentwickler zu den bestbezahltesten Mitarbeitern. Ein entscheidender Faktor ist, dass Softwareentwicklungen sehr komplexe und zeitaufwendige Prozesse sind, was einen Projektverlauf entscheidend beeinflussen kann. Klassische Projektplanung führt oft zu einem unflexiblen und bürokratischen Vorgehen, daher geht der Trend hin zum agilen Projektmanagement – mit Scrum. Aber was ist das eigentlich?
Grenzen klassischer Entwicklungsmethoden
Das hergebrachte Wasserfallmodell bei dem der Entwicklungsprozess aus einzelnen Phasen besteht, stößt an seine Grenzen, wenn flexible Reaktionen gefragt sind oder sich die Umgebungsbedingungen rasch ändern.
Folgende Fragen illustrieren die Herausforderungen:
- Was tun, wenn die Teamgröße zunimmt?
- Wie kann eine optimale Wissensverteilung gewährleistet bleiben?
So entstanden bei der klassischen Methode Schwierigkeiten durch die Ernennung von nur einem Entwickler zum Projektverantwortlichen. Dieser betreute das Projekt von Anfang bis Ende allein, mit der Folge, dass dem Vorgesetzten die Übersicht über den Fortschritt fehlte. Darüber hinaus erforderte die Ein-Mann-Verantwortlichkeit große Anstrengungen bei der Priorisierung der Projekte untereinander, denn es kannten sich immer nur wenige Mitarbeiter in einem Projekt aus. Erschwerend kam hinzu, dass diese häufig mit langlaufenden Tasks arbeitstechnisch schon voll ausgelastet waren.
Im Laufe von Projekten konnte außerdem beobachtet werden, dass die Motivation des Programmierers regelmäßig sank. Die Gründe dafür sind nachvollziehbar: So entstand durch die immer gleiche eintönige Arbeit über lange Zeiträume hinweg eine gewisse Monotonie. Zusätzlich fühlten sich die Projektverantwortlichen teilweise allein gelassen oder überfordert. Unter diesen Voraussetzungen war Führung nur schwer möglich. Denn so wie die Motivation der Entwickler im Projektverlauf abnahm, konnte der Vorgesetzte kaum sinnvoll in das Geschehen eingreifen, geschweige den Projektfortschritt realistisch kontrollieren.
Zunehmende Komplexität und Inselwissen wird zum Problem
Entwicklungsprojekte nehmen normalerweise eine Komplexität an, die es für nicht tiefgreifend beteiligte Personen nahezu unmöglich macht, sinnvolle Entscheidungen für die weitere Vorgehensweise bei der Programmierung zu treffen. Weiterhin fördert eine solche Arbeitsweise die Entstehung von Inselwissen, was in der Vergangenheit bei Krankheit oder der Urlaubsplanung regelmäßig zu Planungsschwierigkeiten führte.
Zuletzt hatten die Entwickler aber auch dieselben Probleme, die für die meisten Prozessreformer in Richtung Scrum die Hauptgründe für einen Umstieg sein dürften: Fehlerhafte Einschätzungen bei der Höhe der Entwicklungsbudgets und die Entwicklung von Spezifikationen die sich nicht vollständig an den Bedürfnissen der Nutzer orientieren.
Vorteile für den Einsatz von Scrum
Unternehmen scheuten trotzdem lange Zeit den Schritt zur Einführung von Scrum. Der Grund für den langfristigen Einsatz der klassischen Entwicklungsmethoden waren Kundenanforderungen, die im Gegensatz zu der Vorgehensweise bei Scrum stehen. Viele Kunden fragen nämlich bereits vor einer Beauftragung nach einem möglichst genauen Maximalpreis sowie nach einer detaillierten, verlässlichen Spezifikation für die jeweilige Anpassung oder Neuentwicklung.
Eine Software nach dem Scrum-Prinzip zu entwickeln, bedeutet für den Kunden zu Beginn weder ein Gesamtbudget noch ein finales Konzept präsentiert zu bekommen. Diese Tatsache mag sich für einige Manager ungewohnt anfühlen, allerdings führt die intensive Zusammenarbeit des Scrum Teams während des Entwicklungsprozesses dazu, dass alle Beteiligten stets eng mit dem Projekt verbunden bleiben.
Der maßgebliche Vorteil für den Einsatz von Scrum in der Entwicklung, lässt sich wie folgt darstellen: Am Ende erhält der Kunde die Software, die er braucht und nicht eine, die nur anhand von Spezifikationen entwickelt wurde.
Darüber hinaus führt das schrittweise Vorgehen bei Scrum dazu, dass die Entwicklung einer Anwendung für den Kunden im Schnitt nicht nur günstiger ist, sondern sie ist optimal an seine Anforderungen angepasst. Ein weiterer Vorteil zeigt sich im frühzeitigen Ausprobieren der Software. Hierbei hat der Kunde die Möglichkeit, den Entwicklungsprozess nach jedem Sprint zu beenden, wenn die Software seiner Meinung nach genug Features enthält.
Der Scrum-Prozess – Motivation durch Selbstorganisation
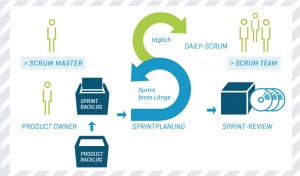
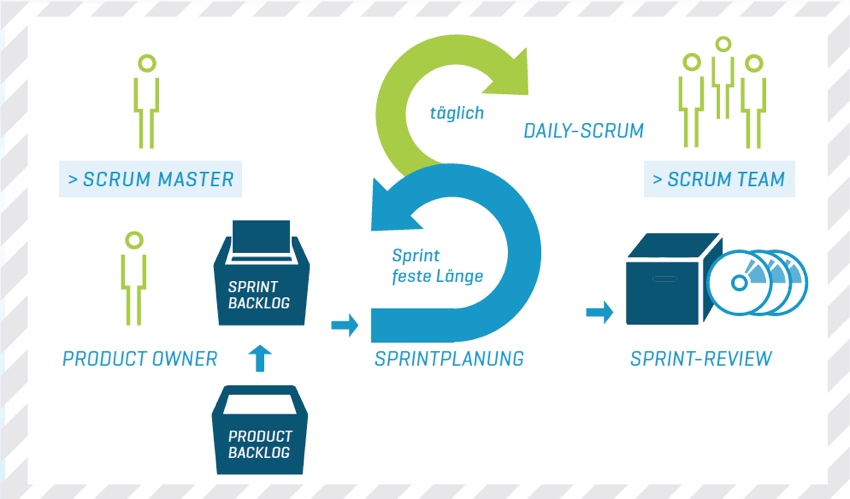
BU: Scrum-Prozess bei der ADACOR
Scrum unterscheidet drei Rollen: Product Owner (Software-Verantwortlicher auf Kundenseite), Entwicklungsteam (Unternehmen) und Scrum Master. Der Scrum Master unterstützt den Workflow in erster Linie als Moderator. Außerdem führt er die Scrum-Regeln ein und überprüft deren Einhaltung. Der Scrum Master gibt den Teammitgliedern keine Anweisungen. Obwohl der Scrum-Prozess einem festen Regelwerk sowie Priorisierungsvorgaben des Management beziehungsweise des Product Owner unterliegt, entscheiden die einzelnen Entwickler unter Berücksichtigung dieser Vorgaben relativ eigenständig, was sie in den nächsten Sprint aufnehmen wollen. In der praktischen Umsetzung zeigt sich, dass die Selbstorganisation zu einer enormen Motivationssteigerung bei den Entwicklern führt. Häufig nehmen diese sich eher zu viel vor als zu wenig. Es kommt sogar vor, dass sie früher als geplant ein selbst gestecktes Ziel erreichen, sofern der Vorgesetzte den Sprint nicht unterbricht und damit das Commitment hinfällig wird.
Sprint: Fester Zeitraum zur Umsetzung von Anforderungen
Ein Sprint ist ein Arbeitsschritt mit einer im Vorfeld festgelegten Zeitdauer, bei der ADACOR Hosting sind das zwei Wochen. Vor jedem Sprint plant das Scrum Team die Inhalte für den nächsten Sprint. Dabei folgen die Sprints immer direkt aufeinander. Dieses Vorgehen bietet verschiedene Vorteile: Die Zwei-Wochen-Schritte ermöglichen flexibles Handeln, sodass im Vorfeld kein fertiges Konzept erforderlich ist. Das Sprint Team benötigt vom Kunden nur eine Vision und eine User Story (Anforderungen im Product Backlog). Diese Anforderungen aus Kundensicht werden immer mit dem Kunden zusammen erarbeitet. Das Sprint Team erarbeitet im Sprint-Kick-off aus den User Storys anschließend die konkreten Tasks für das Sprint Backlog.
Unterstützt wird ein Sprint durch Daily-Scrum-Meetings. Dabei treffen sich das Entwicklerteam – sowie bei Bedarf der Scrum Master und/oder der Product Owner – täglich zu Arbeitsbeginn zu einem etwa 15-minütigen Informationsaustausch. Hier werden keine Probleme gelöst, sondern es geht für die Teilnehmer darum, sich einen Überblick über den aktuellen Stand der Arbeit zu verschaffen.
Der Sprint endet nach zwei Wochen mit einem Review (Prüfung aller Anforderungen, die bisher im Rahmen der Sprints fertiggestellt wurden), um das Product Backlog bei Bedarf anpassen zu können beziehungsweise einer Retrospektive, die kritische Überprüfung der bisherigen Arbeitsweise, innerhalb des Teams sowie einem Ergebnisreport an die Stakeholder (Kunde, Anwender, Management). Damit bietet der Prozess für alle Beteiligten eine hohe Transparenz und die Gelegenheit, sich laufend über den Realisationsfortschritt zu informieren. Bei gleichzeitiger Anwendung des Konzepts der kontinuierlichen Integration (im Englischen bekannt als „continuous integration“) werden alle funktionierenden und abgenommenen Teile der entwickelten Software sogar sofort nach dem Sprint Review in das Produktivsystem eingespielt und damit direkt unter Produktivbedingungen getestet und eingesetzt. Hierdurch kann die Software noch besser und genauer auf die Nutzeranforderungen abgestimmt werden. Das Konzept eignet sich jedoch nicht für sehr betriebskritische Applikationen.
Als sehr positiv erweist sich beim Einsatz von Scrum die Wissensverteilung innerhalb des Sprint Teams. Gab es vor dem Umstieg oft die Situation, dass sich zu wenige Mitarbeiter mit einem Projekt auskannten und das Wissen schlecht verteilt war, führt die Selbstorganisation zu einer automatischen Wissensverteilung im Sprint Team, ohne dass dies der Vorgesetzte forcieren muss. Im Unternehmen wurde dieser Effekt durch den zusätzlichen Einsatz von Pair Programming als erwünschtes Konzept im Sprint noch verstärkt.
Fazit – vermeintlicher Nachteil verkehrt sich in Vorteil
Die Performance im Entwicklungsbereich hat sich durch Scrum insgesamt verbessert und die Arbeitsprozesse verlaufen generell reibungsloser.
Nachteilig ist bei Scrum auf den ersten Blick, dass zu Beginn weder die Gesamtkosten noch ein konkreter Umsetzungszeitraum genannt werden können. Dieser Nachteil verkehrt sich jedoch zu einem Vorteil, denn Schätzungen großer Projekte sind grundsätzlich aufwendig und ungenau. Darüber hinaus verlangen Entwickler stets hohe Sicherheitsaufschläge, um die Unsicherheit bei der Schätzung zu kompensieren. Bei Anwendung des Scrum-Prinzips und einer Bezahlung nach Aufwand, entfällt der Sicherheitsaufschlag für den Kunden.